在SEO界中,树状结构这个名词倒是名声很大,但是真正理解其含义的seo相信不太多,或者说多数人都只知其一不知其二,包括笔者在今天之前还对他有一定的遍见,今天在看一篇文章之后才真正的了解了树状的结构。
常规的树状的理解是:
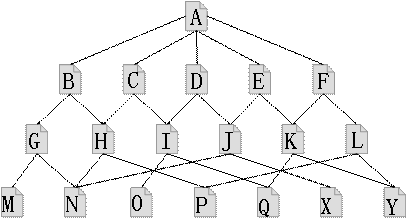
整体的树状结构

内容页面结构树状图
而这样子,对google而言是否就传说中的那么友好呢?
下面这句是摘之google黑板报的:
你的网站上是否有一个日历表,上面的链接指向无数个过去和将来的日期(每一个链接地址都独一无二)?你的网页地址是否在加入一个&page=3563的参数之后,仍然可以返回200代码,哪怕根本没有这么多页?如果是这样的话,你的网站上就出现了所谓的“无限空间”,这种情况会浪费抓取机器人和你的网站的带宽。
从此断中我们了解到,google蜘蛛在爬行我们网站的时候,因为网站的结构太交叉而增加虫虫的爬行重复性呢?在google蜘蛛分配的有限时间里面,做了太多的无谓的爬行,浪费掉了大量时间。虽然可能页面多收录了一些,但本质的东西占有率将被大大的稀释掉了。
通过使用你的robots.txt 文件,你可以阻止你的登录页面,联系方式,购物车以及其他一些爬虫不能处理的页面被抓取。(爬虫是以他的吝啬和害羞而著名,所以一般他们不会自己 “往购物车里添加货物” 或者 “联系我们”)。通过这种方式,你可以让爬虫花费更多的时间抓取你的网站上他们能够处理的内容。
比如:服装的产品:分类可以为:男装的,女装的,春装,冬装,时尚的,稳重的等等分类,还有按价格段分类,及热门产品,最新产品,推荐产品等分类。其实其中一部份产品包括了上面的若干项分类,那么难免在爬行的时候会交叉,那么我们可以把分类都用robot屏蔽起来,只让google爬行产品的总分类,那么就免去了一些无谓的撞车事件,从而对google更友好了。
好啦,这样子在google眼里你的站总算到达了真正的树状结构:(树状:从根部到任何一片叶子只有唯一的一条路能到达。)
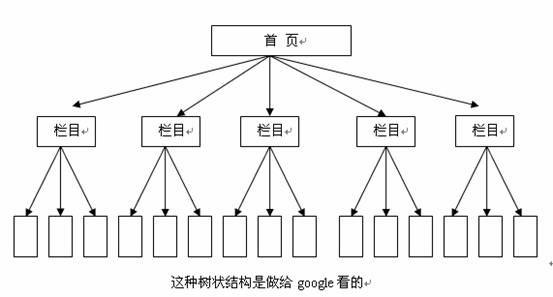
只有这样子,爬虫就不会撞车,就更有效率。
存在的问题:这样子,虽然减少了网站爬行中的冗余度,从某种程度上减少了Google的收录量。